 Skip to content
Skip to content
物体检测是一种基于计算机视觉的人工智能技术,拥有非常多的应用场景。通常的物体检测训练流程需要将数据存储在云端进行集中化训练。然而,出于对隐私问题和传输视频数据的高成本的考量,在集中式存储的大型训练集上使用现有方法来建立物体检测模型是非常具有挑战性的。
为了将机器学习的需求与在云端存储大量数据的需求分离开,一个新的被称为联邦学习的机器学习框架被提了出来。联邦学习提供了一种非常有前景的可以用于模型训练的方法,这种方法无需对数据的隐私性以及安全性做出妥协。尽管如此,对于那些不是联邦学习领域专家的计算机视觉应用开发者来说,现阶段缺乏一个易于使用的工具让他们可以方便地在他们的系统中应用联邦学习。
这里我们介绍一个微众银行和极视角公司联合开发的物体检测平台。据我们所知,这是第一个联邦学习在计算机视觉任务中的实际应用。
FedVision —— 一个基于联邦学习的在线视觉物体检测平台
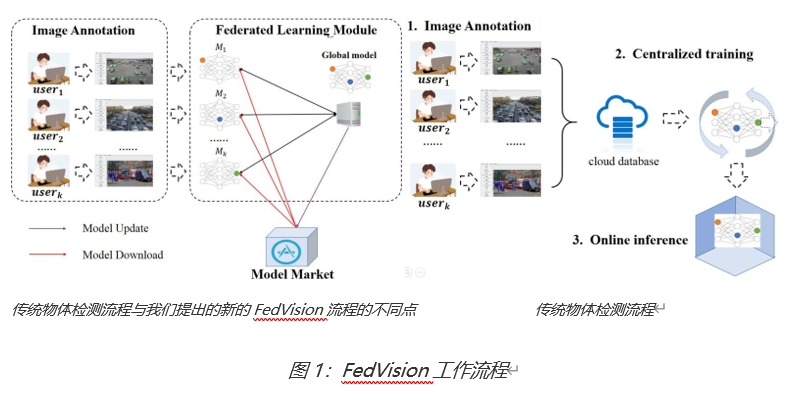
图1(右)展示了我们的FedVision的工作流程。它包含了三个主要步骤:1)众包的图像标注,2)联邦模型训练,和3)联邦模型更新。
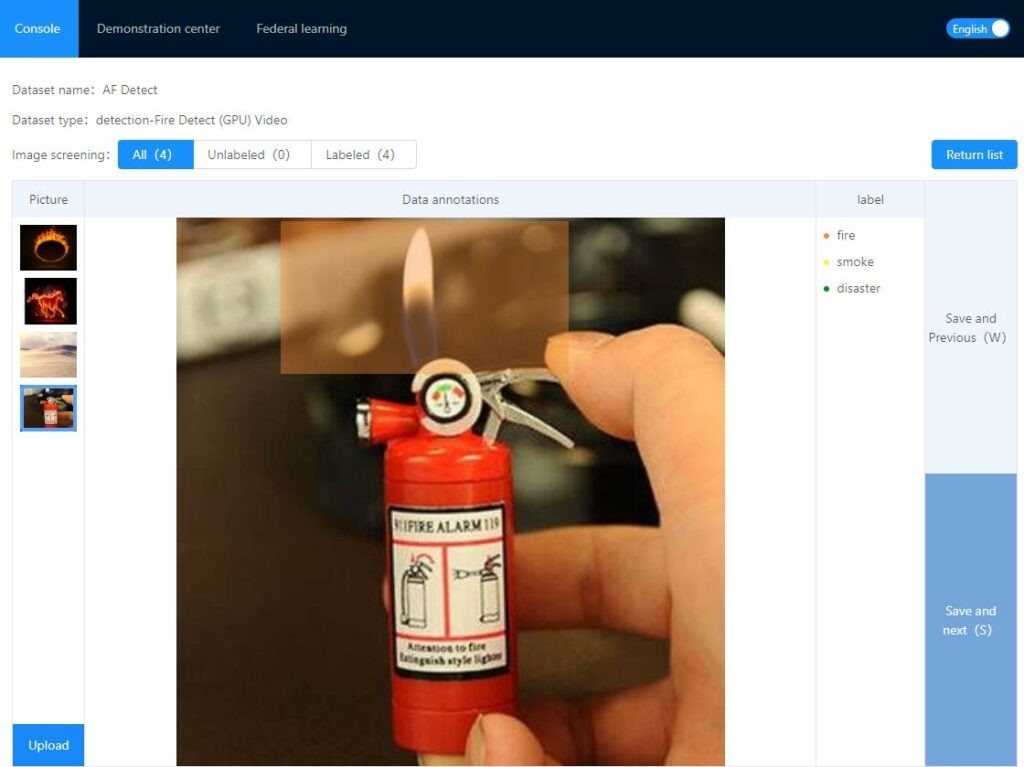
- 众包的模型标注 这个模块的设计让数据拥有者可以容易地为联邦模型训练而标注本地存储的数据。如图2所示,一个用户可以在其本地设备上使用FedVision提供的客户端来标注一张给定的图片。
- 联邦模型训练
从系统工程角度来看,联邦模型训练包含了如下六个模块。
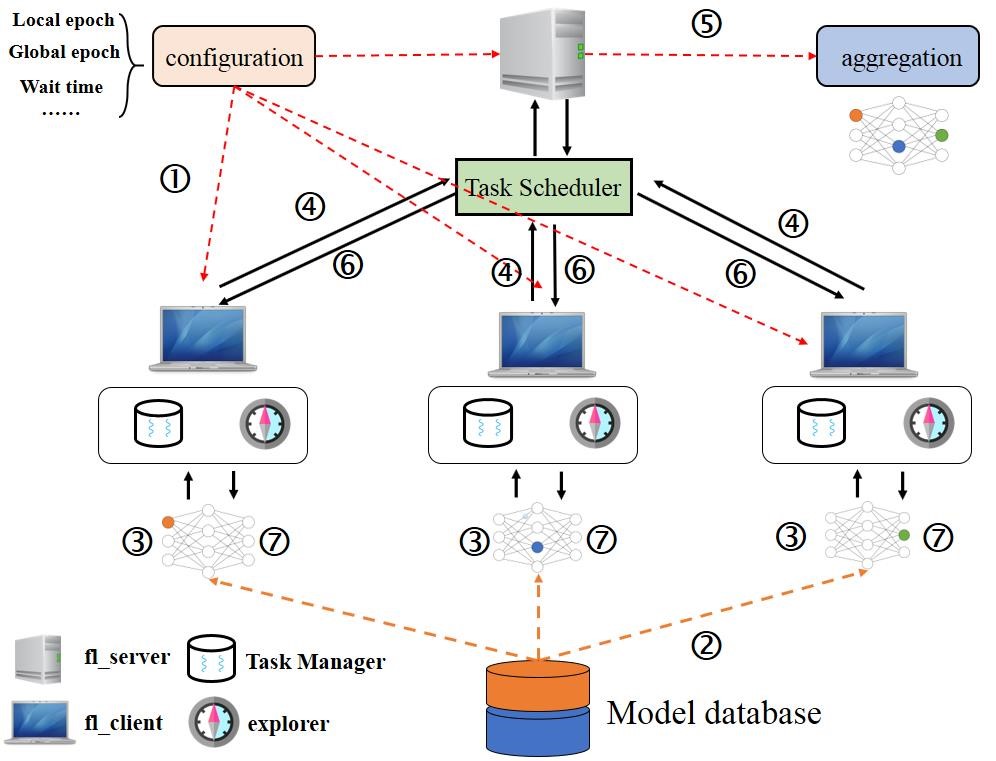
- 配置模块:这个模块允许用户配置训练信息,比如迭代次数、重连接次数、用于更新模型参数的服务器端的URL和其他关键参数。
- 任务调度模块:这个模块执行全局的分发调度,用于协调联邦学习服务器和客户端之间的通信,从而在联邦模型训练的过程中平衡本地计算资源的使用。这个负载均衡的方法基于一种最大化最终联邦模型质量的策略。这个策略综合考虑了客户端本地模型的质量和它们当前的本地计算资源的负载。
- 任务管理模块:当多个算法模型被客户端同时训练时,这个模块会对这些并存的联邦模型训练过程进行调度。
- 监督模块:这个模块会在客户端侧监督资源使用状况(比如CPU使用、内存使用、网络负载等等),通过将这些信息通知任务调度模块,来帮助其进行负载均衡的决策。
- 联邦学习服务端:这个就是联邦学习的服务器。它负责联邦学习中非常重要的步骤,包括模型参数的更新、模型聚合和模型分发。
- 联邦学习客户端:这个部分承载了任务管理模块和监督模块的工作,以及执行本地模型训练(这也是联邦学习的一个非常重要的步骤)。
物体检测:
物体检测算法是FedVision平台的核心。它是一个与计算机视觉和图像处理有关的计算机技术,可以在图像和视频中检测某种类别的语义物体的实例。在过去的十年中,有许多关于物体检测的研究课题被提出,并在很多商业应用案例中取得了前所未有的成功。这里以YOLOv3为例,我们在图5中展示了其网络结构。

[图4:使用YOLOv3进行火焰检测]
YOLOv3的方法可以被总结为如下步骤:给定一张图片,比如图4中的火焰图片,它首先将这张图片分割成s*s的网格,每个网格都被用于使用其中间图像来检测目标物体(在图4中的蓝色方块网格被用于去检测火焰)。对于每个网格来说,这个算法执行如下的计算:
- 预测B边界框的位置。每个边界框被描述为一个四元组(x,y,w,h),其中(x,y)是这个框的中心坐标,(w,h)分别代表这个边界框的宽度和长度。
- 估计被预测出来的所有的B边界框的置信度。这个置信度由两部分构成:1)是否一个边界框包含了目标物体,和2)这个框的边界有多精确。第一部分可以被描述为p(obj)。如果这个边界框包含了目标物体,那么p(obj)=1。这个被预测出来的边界框的精度可以通过其与真实边界框的的交并比(IOU)值计算出来。
- 对于所有C个类别,计算每一个类别的条件概率,p(c_ij | obj) $\in$ [0,1]
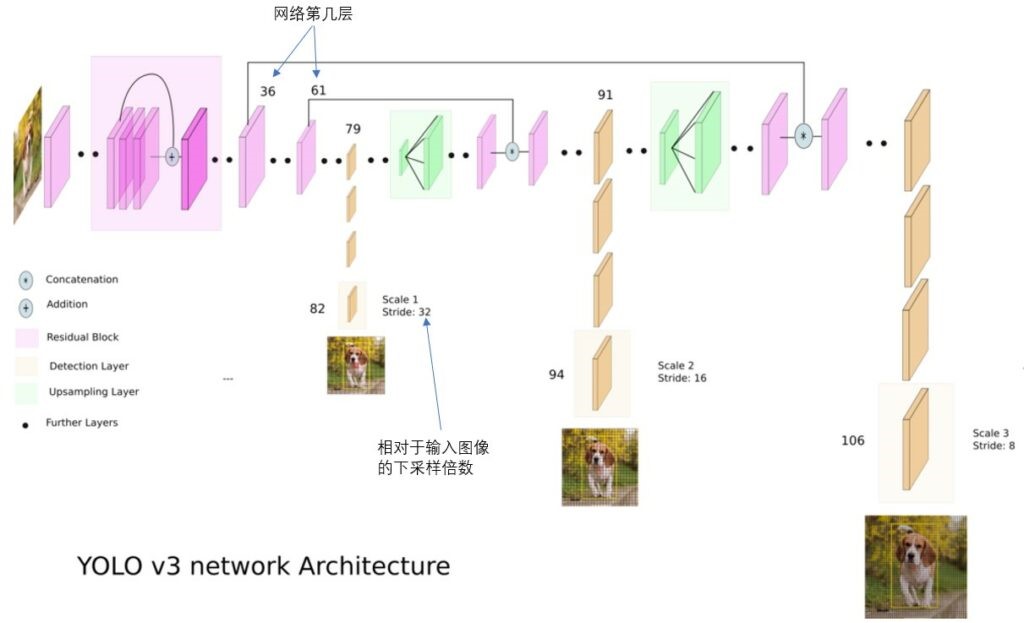
[图5:YOLOv3的网络结构]
联邦学习
为了理解包含在FedVision平台中的联邦学习技术,我们在这里介绍下横向联邦学习(HFL)的基本概念。HFL,也被称之为基于样本的联邦学习,可以被应用于所有数据集拥有相同的特征空间但在样本空间却不同的场景(图4)。换句话说,不同的参与方拥有同样格式的数据集,但这些数据集是从不同的数据源采集的。在这里,因为HFL的目标在于帮助不同的参与方(也就是数据拥有者)将具有同样特征空间的数据(也就是有标注的图像数据)联合起来训练联邦物体检测模型,所以HFL很适用于FedVision的应用场景。“横向”这个词来源于“横向分区”这个术语,此术语被广泛地用于传统表类数据库的相关概念中(也就是数据表的行被横向分割成不同的组,并且每行包含了全部的数据特征)。如下我们总结了有两个参与方的HFL的情况(对其他情况也适用)。
![]()
其中两个参与方的数据特征和标签(Xa;Ya)和(Xb;Yb)是相同的,但是数据数据实体ID Ia和Ib是不同的。Da和Db表示数据集被参与方A和参与方B分别拥有。
在HFL下,被各个参与方所采集并存储的数据不再需要被上传到一个通用服务器去进行模型训练。相反,算法模型被联邦学习服务器发送到每个参与方,然后被参与方使用本地数据进行再训练。当训练收敛后,各个参与方把被加密的模型参数发送回服务端。然后,这些模型参数被聚合到一个全局的联邦模型中。这个全局联邦模型将会最终被分发给联邦中的各个参与方以进行后续的推断过程。