 Skip to content
Skip to content
反洗钱在银行的日常经营中发挥着重要作用。有效的反洗钱模型可以遏制经济犯罪活动。然而,确定一个交易记录是否是洗钱活动,这一过程是繁复且乏味的,并且极其容易出错。传统方法上,银行会使用基于规则的模型来过滤那些明显的非洗钱记录,并手动审查其他记录。
基于规则的模型确实发挥了很大的作用,但由于覆盖范围小,仍然需要在剩余大量的样本中进行人工审查,因而花费大量的时间。此外,虽然它在已知的传统案例中很有效,但在面对新的未知案例时,就会难以察觉其行为是否违法。因此,利用机器学习模型,找到所有特征之间不可见的关联成为了新的手段。
微众银行作为中国第一家互联网银行,目前正在利用逻辑回归模型等机器学习模型,使用的特征数多达900多种,有效地覆盖了人们日常金融活动的方方面面,对未知的洗钱方法有很好的挖掘作用。然而,这些模型由于缺乏数据(更具体地说,是洗钱的案例)而准确率受损。由于没有大量的实证案例,模型的评价性能很差,很难获得对未知案例的推理能力。
后来,微众银行引入了一种称为联邦学习的新方法来解决这个问题。联合学习使多个机构能够在不物理共享数据的情况下构建一个通用模型。为了实现这一目标,微众银行人工智能部门自研了全球首个联邦学习工业级的开源框架——FATE(Federated AI Technology Enabler)。
在FATE的帮助下,可以联合多家银行共同培养反洗钱模式。这种合作的过程可以描述如下:

这个联邦训练模型称为横向逻辑回归(Homo-LR)。所有银行都提供相同特征维度的数据,这意味着它们具有相同的特征和不同的样本ID。通过这种组合,整个数据集包含了大量的实证案例,使模型表现良好。homo-LR的原理如下所示。
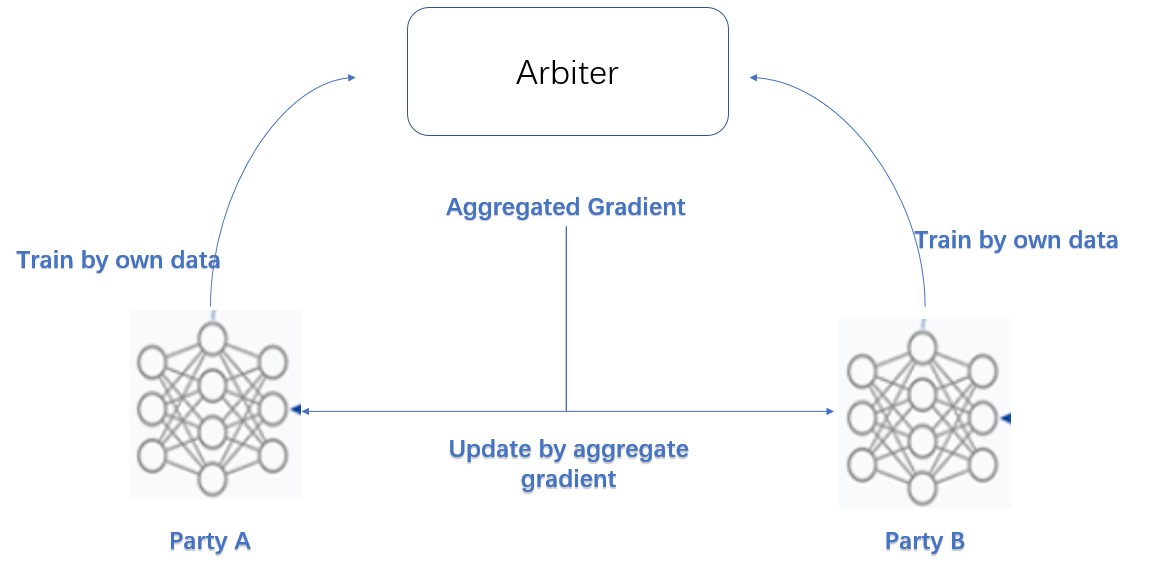
在每次迭代中,每一方都通过自己的数据训练模型,并将模型权重或梯度发送给称为协助者(arbiter)的第三方。Arbiter聚合所有这些模型权重或梯度,然后更新回每一方。当模型由各方训练时,各方的数据不会离开本地。
推理过程也很容易理解和执行。
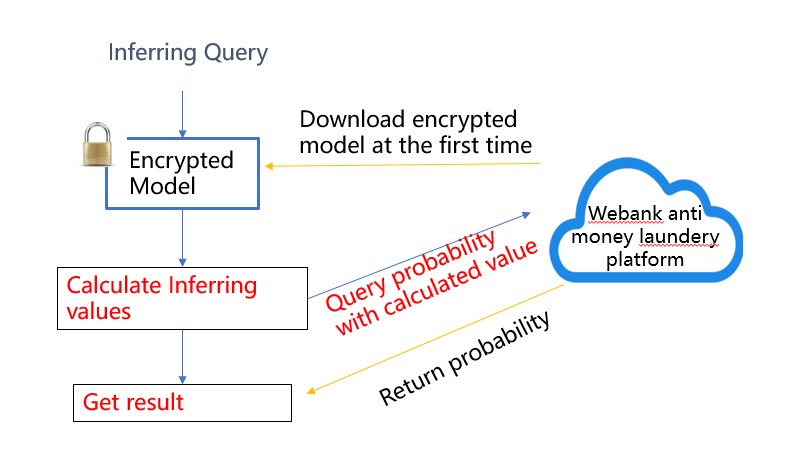
通过测试,我们证明这样的建模合作方式取得了巨大的成功,极大地提高了模型的性能。lr模型的AUC增加了14%,显著减少了手工评审的工作量和难度。
下图是使用关节模型前后的效果比较。每个方格的数字代表洗钱案件的可能性。
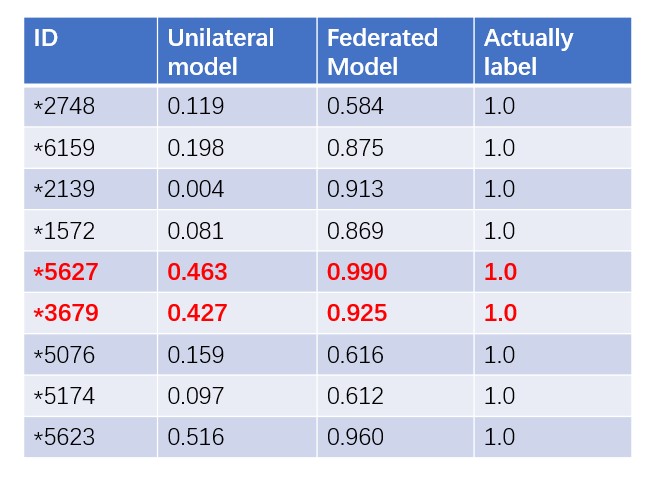
如果采用传统的单边模式,这些案件就不能被认定为可疑案件。然后,在回顾两起红色案件的具体情况时,发现它们具有非法结算型地下钱庄的特点,利用我国电子银行账户进行过渡的可能性较大。
此外,AUC随建模数据的增加而增加,从而提高了对数据增长的需求。
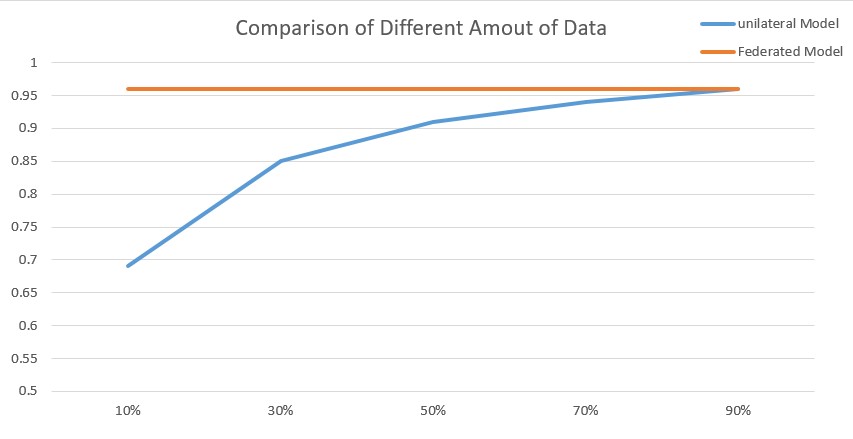
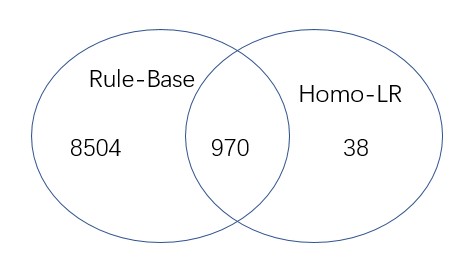
因此,如果我们只使用基于规则的模型,每天需要审查一千多个案例。然而,随着联邦homo-LR的使用,这个数字已经减少到38。
利用FATE,我们创造性地解决了数据孤岛问题,极大地拓展了人工智能的应用范围。同时还更好地保护用户隐私和机构数据安全。